Introduction
We live in the era of information overload, we consume massive amounts of information from different sources in a daily basis, but how do we find interesting stuff inside these information? How do we discover an interesting book out of the millions of books available in Amazon? How do we chose a nice pair of shoes out of the hundreds of thousands in Zalando? An interesting book for me might be a boring book for you, and a particular pair of shoes that is cool for me might be not your taste. Recommender Systems deal with problems like that, such a system uses previous purchases and user interaction to prescribe the user with items that most likely she would like to consume.
The core problem of recommender systems is to estimate a utility function that would predict how much a user would like an item, such a function takes into consideration previous purchases, user-site interaction, user-user interaction, item similarity based on their content, the context of a specific user session and other attributes.
Collaborative filtering
A popular algorithm that uses only previous purchases/behavior is collaborative filtering. On the collaborative filtering setting we have n user, m items and r ratings, those ratings can be collected either explicitly (e.g. stars in Amazon) or implicitly from user behavior (e.g. purchasing an item is better rating than putting it on the wish list which is better than just clicking the item without further actions). This kind of information is represented in a user-item matrix similar to the following example :
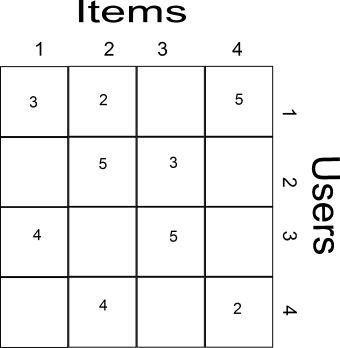
This matrix is a sparse matrix because not all users had rated all items. The aim of a recommender system is to fill this matrix. In collaborative filtering the items are modeled as vectors of the user ratings, therefore by using a similarity measure (e.g. cosine similarity) we can compute how similar are two items. A predicted rating is the weighted similarity of a user with an item (we give more emphasis on items that were more likable to the corresponding user). In the above example we have ![i_1 = [3,0,4,0]](https://s0.wp.com/latex.php?latex=i_1+%3D+%5B3%2C0%2C4%2C0%5D&bg=ffffff&fg=424242&s=0&c=20201002)
![i_2=[2,5,0,4]](https://s0.wp.com/latex.php?latex=i_2%3D%5B2%2C5%2C0%2C4%5D&bg=ffffff&fg=424242&s=0&c=20201002)
![i_3=[0,3,5,0]](https://s0.wp.com/latex.php?latex=i_3%3D%5B0%2C3%2C5%2C0%5D&bg=ffffff&fg=424242&s=0&c=20201002)
![i_4=[5,0,0,2]](https://s0.wp.com/latex.php?latex=i_4%3D%5B5%2C0%2C0%2C2%5D&bg=ffffff&fg=424242&s=0&c=20201002)






The advantage is collaborative filtering is that it does not require a lot of domain knowledge and content extraction. On the other hand, requires a lot of ratings beforehand in order to perform well, because it suffers a lot of sparsity. Imagine having an inventory of millions of items, then the chances that items got rated from same users are very low. A way to overcome this problem is to use latent factors instead of the items in order to make recommendations, we can think of those latent factors as topics, e.g. for movies we would have Comedy, Horror, Romance, and others. These topics could reduce the dimensionality of our problem from millions of items to hundreds of factors and therefore suffer less from sparsity.
Model-based collaborative filtering
Model-based collaborative filtering (AKA supervised matrix factorization) is a way to learn the latent topics from the ratings given by users. As before, we have a triplets of user rated item with a particular rating 











S is the set of the known ratings. The regularization term helps us to avoid overfitting. The above objective function is a non-convex one. In order to solve such a minimization problem, we follow the alternating least squares principle, i.e. we fix the one set of parameters, minimize the with respect to the other (this makes the objective function a convex one), then we fix the other set of parameters and minimize with respect to the first ones, we iterate until the objective function does not decrease any more. Additionally, we can use stochastic gradient descent to speed-up the minimization of the above objective function. In such a case, we iterate over our ratings 


Where 
Model-based collaborative filtering and related methods are one of the most popular approaches to recommendations but their main disadvantage is the cold start problem meaning that when a new user we cannot recommend him anything, and a new item will never be recommended. In order to overcome such a problem collaborative filtering is often hybridized with approaches such as content based recommendations or popularity (e.g. “blockbuster”) recommendations for new items and users.
 observations
observations  that we would like to cluster in
that we would like to cluster in  groups. In the case of a Gaussian Mixture Model we have
groups. In the case of a Gaussian Mixture Model we have  and covariance
and covariance  . Our model has also component priors
. Our model has also component priors  that sum to one. The grouping that we do not know is represented as latent variables
that sum to one. The grouping that we do not know is represented as latent variables  , e.g.
, e.g. ![z_i = [0,1,0]^T](https://s0.wp.com/latex.php?latex=z_i+%3D+%5B0%2C1%2C0%5D%5ET&bg=ffffff&fg=424242&s=0&c=20201002) means that distribution 2 is responsible for generating
means that distribution 2 is responsible for generating  .
.
 for all components. One popular approach is Maximum Likelihood Estimation, i.e. we will take the parameters that maximize the likelihood:
for all components. One popular approach is Maximum Likelihood Estimation, i.e. we will take the parameters that maximize the likelihood:

 is the posterior of the latent variables, i.e. the probability that component
is the posterior of the latent variables, i.e. the probability that component 







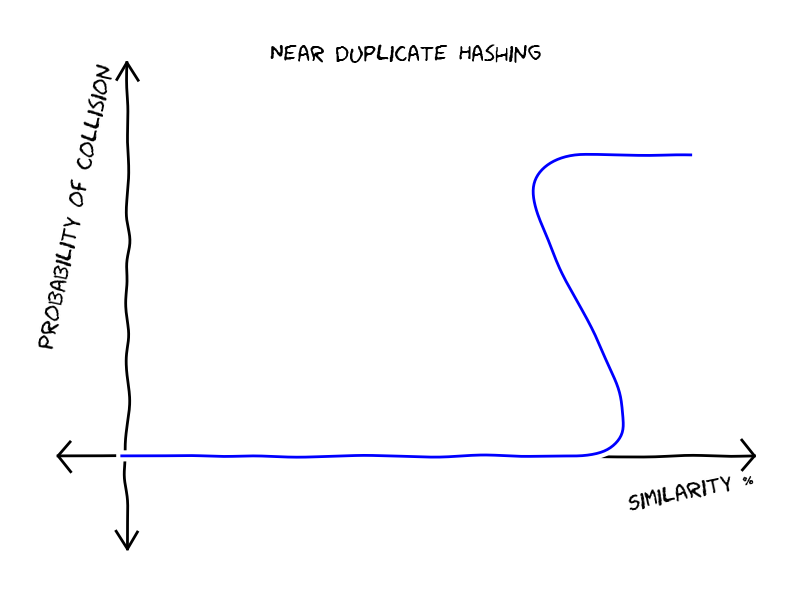
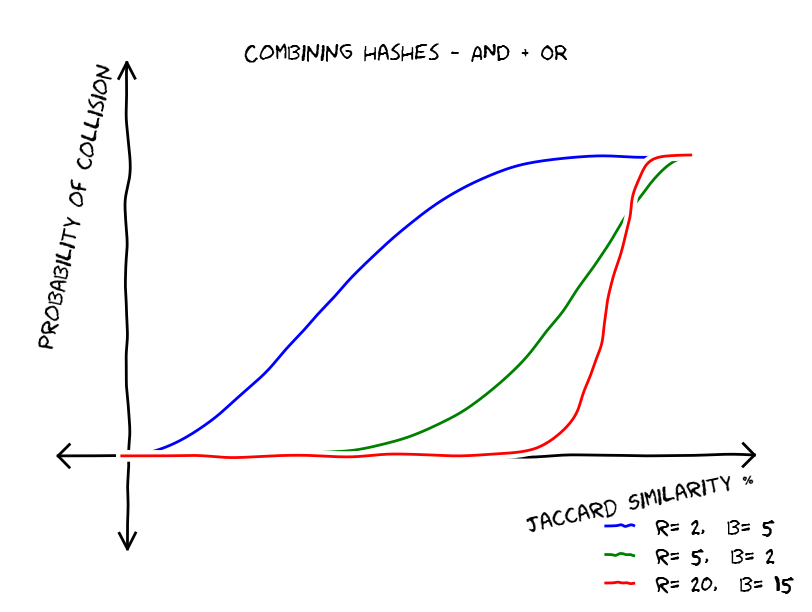
 . As we can see by the following graph this trick reduced false positives but gave us more false negatives.
. As we can see by the following graph this trick reduced false positives but gave us more false negatives.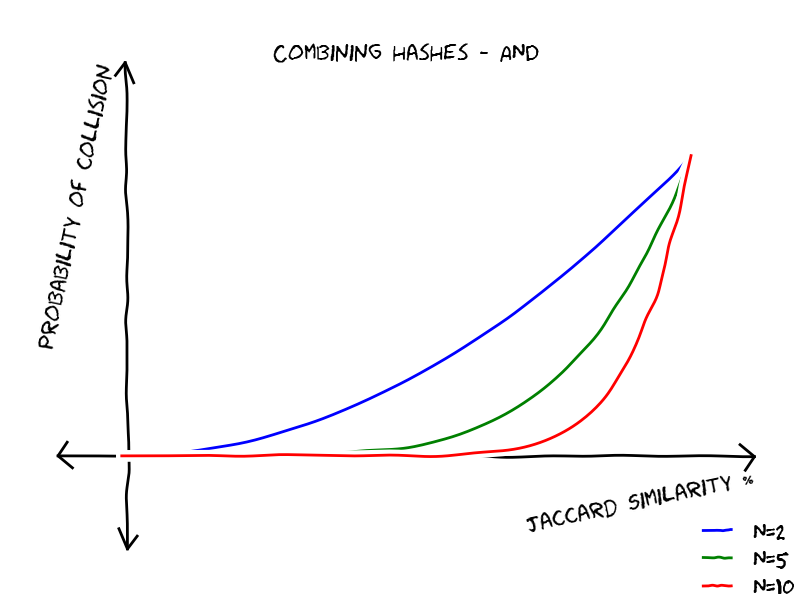
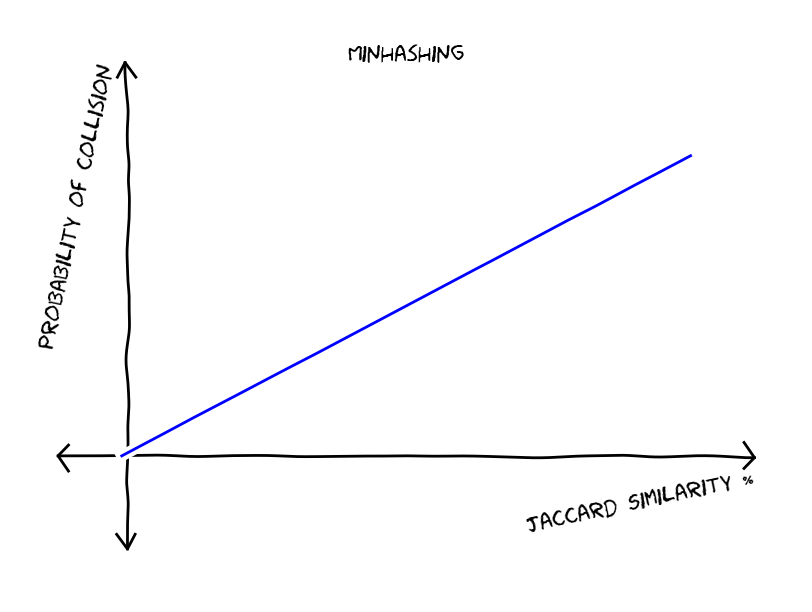
 , then the probability that at least one chunk collides is equal to
, then the probability that at least one chunk collides is equal to  . This gives us the following type of functions, these functions reduce false negatives but increase false positives.
. This gives us the following type of functions, these functions reduce false negatives but increase false positives.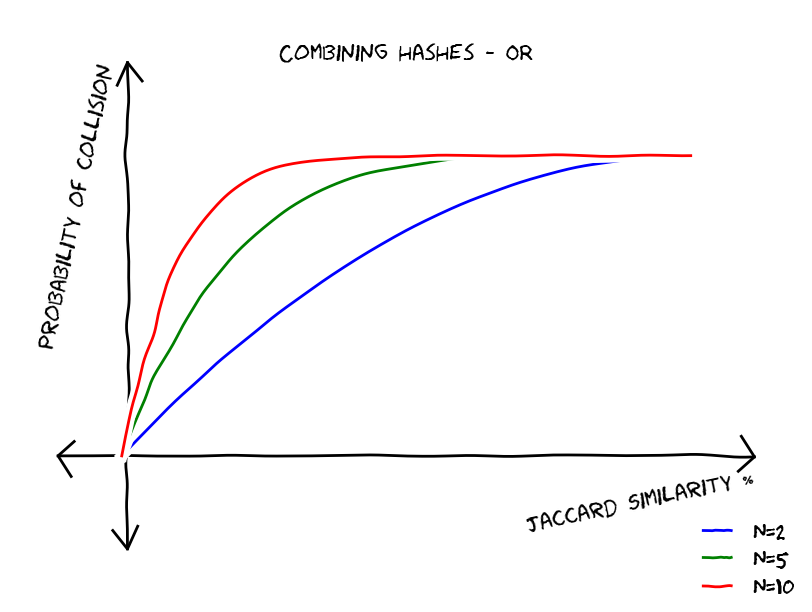
 AND combinations followed by
AND combinations followed by  OR combinations. What does this mean? We break our files into
OR combinations. What does this mean? We break our files into  chunks, lets say we have
chunks, lets say we have  . The probability of having zero band collisions is equal to
. The probability of having zero band collisions is equal to  , this makes the probability of having at least one band collision equal to
, this makes the probability of having at least one band collision equal to  . This gives the following graphs:
. This gives the following graphs: